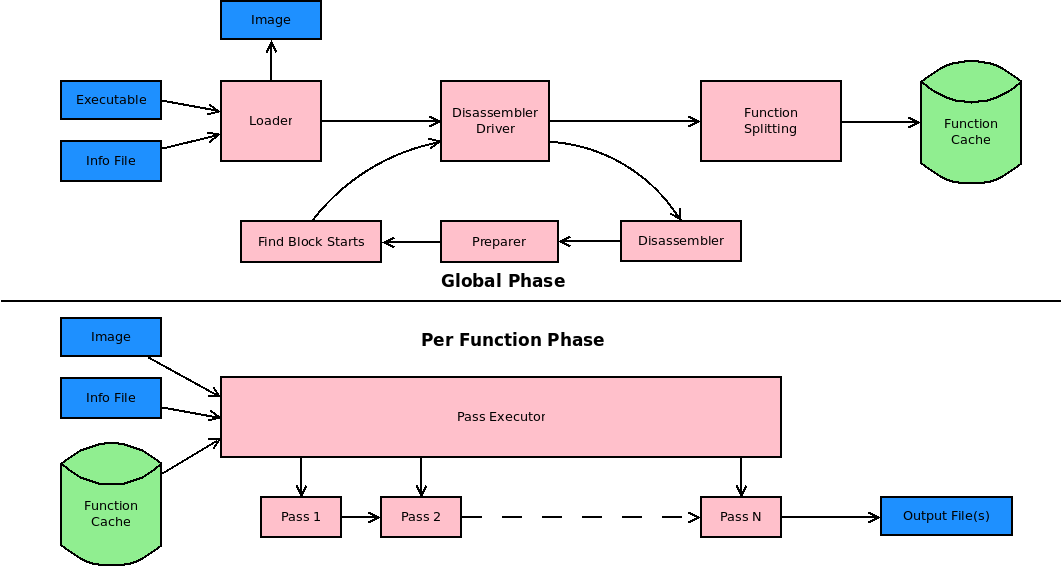
Overview
Well there are multiple representations: a linear list of assembler lines, assembler lines in blocks, blocks of statements and high level control flow instructions (internally named Regions). The first two are nothing special and the last is worth a blog entry of its own. So this blog post is about blocks of statements. One indicator that this is the default representation is that it doesn’t have its own name in the holdec code. Let us call it IR in this blog post.
The IR represents one function and one can be seen three different levels. The first level is that a function consists of a set of blocks. Each block has a list of statements which can be empty and a list of jumps. A jump consists of the target block id and an optional condition. With this first level the code performs most of the CFG algorithms.
The second level of the IR is about the meat in each block in the form of statements. The two most common statement types are assignment and return. The assignment has a RHS (an expression) and an optional LHS (a register). The return statement has an optional return value which is also an expression. This level is used by data flow analysis and is relevant for SSA.
This brings us to the third level: the expressions. There are dozens of expression types like add, sin, register, function-call or load. An expression is a tree. Leaf types are for example a global variable, a register or an integer value. Most of the expression types however are not leaf types but form the inner tree nodes. Each expression has a basic type (integer of various widths but without information about signedness, float of various sizes, bool/single bit, void but no pointer). This basic type is always there and is always checked unlike the full type analysis which is optional. Simplification for example takes place in this level.
This design worked out quite well in the past. In the following I want to go over some details in an unordered way after describing the expressions in more detail.
Expression types
Leaf types
- Concrete values can be integer, float, boolean and string (think printf format string).
- There is an expression type for a function. A function call expression uses this if the function is known and not computed.
- Global variable
- Name used for accessing structs and co.
- NOT_MODELED (holdec doesn’t model some semantics), UNDEF (CPU documentation says that the value is undefined) and TRASHED (eflags after a function call). All three are undefined for ISDEF(x).
- A parameter: used to access the parameter value in the called function. Is independent of the parameter transfer place.
- Register expression: an important expression type
There are some additional helper expressions: an expression for the initial stack pointer, the initial value (used for all other CPU registers to detect passed values) or an expression for the fake edge from an infinite loop to the exit block.
Integer arithmetic
- ABS(x): rarely used
- NEG(x): can also be used for floats.
- ADD(x,y) : can have more than two children. Can also be used for floats.
- ADD_OVERFLOW_SIGNED(x,y): returns a bool
- SUB(x,y): can also be used for floats
- SUB_BORROWS_SIGNED(x,y): returns a bool
- SMULT(x,y), UMULT(x,y): signed and unsigned multiply, can have more than two children
- SDIV(x,y), UDIV(x,y): signed and unsigned division
- SMOD(x,y), UMOD(x,y): signed and unsigned remainder
Integer bitwise
- AND(x,y): can have more than two children
- NOT(x)
- OR(x,y): can have more than two children
- XOR(x,y): can have more than two children
Integer shift and rotate
- SHL(src, count): shift left
- SSHR(src,count), USHR(src,count): signed and unsigned shift right
There are four rotate expressions but these are only used by M68k. It looks like the M68k part can be changed to behave like the ia32 part (which converts them to shifts).
Boolean operations
- BAND(x,y): boolean and. Can have more than two children.
- BOR(x,y): boolean or. Can have more than two children.
- BXOR(x,y): boolean xor. Can have more than two children. Can be used to nicely compute the parity bit. Could be replaced with CMP(x!=y).
- BNOT(x): negate the boolean
Only top-level expressions can have side-effects and so for example not the children of BAND. Therefore the short circuit effect of && or || from C are not relevant here.
Comparison
- CMP(value1, relation, value2): can be used for integer and booleans. Relation is one of ==, != or signed/unsigned <,>,<=,>=. Has a very large number of simplification rules.
- FCMP(value1, relation, value2): can be used for floats. Relation is one of ==, !=, <,>,<=,>=.
Both comparison expression types return a boolean.
Float operations
- ADD, SUB and NEG from above
- FMULT(x,y)
- FDIV(x,y)
- SIN(x)
- FLOAT_ISINFINITE(x)
The list will grow when x87 is fully implemented. Or maybe not when the additional instructions are expressed with builtin functions.
Type conversions
- NARROW(x): just takes the lower bits (as much as the target type has)
- WIDEN(x), UNSIGNED_EXTEND(x): prefix the value with zeros
- SIGNED_EXTEND(x): repeat the MSB
- BIT_TO_INT(x): fancy way of saying “!!x” or “x?1:0” but can be helpful since the target value range is known to be 0 or 1.
- SIGNED_INT_TO_FLOAT(x) and UNSIGNED_INT_TO_FLOAT(x): pretty clear
- FLOAT_TO_SIGNED_INT(x) and FLOAT_TO_UNSIGNED_INT(x): this is currently a bit rough. Either add a rounding mode as a parameter or have for each rounding mode a separate expression or make sure that always a rounding is performed before.
- INT_TO_FLOATBITS(x), FLOATBITS_TO_INT(x): the bit size and the bit pattern stays the same but the type and therefore the interpretation of the bit pattern changes.
- FLOAT_NARROW(x) and FLOAT_WIDEN(x): for converting between different float types
- COMBINE_HIGH_LOW(high,low): just paste these two together
Memory related
- LOAD(addr): reads a value from memory. For special memory access (like “ldar” from AARCH64) builtin functions are used. The lock prefix of ia32 is currently ignored.
- STORE(addr, value): writes a value to memory
- ADDR(var): gets the address of global variable, local variable or a parameter.
Other expression types
- F_CALL(func, para1, para2,…): a function call
- PHI(x,y): for SSA. Can have more than two children.
- BIT_SET(bitNo, src, bitValue): updates a bit in src to a new value
- BIT_TEST(bitNo, src): queries one bit in src
- COMBINE_BITS(bit1, bit2, bit3,…): Can be used to model bytes with undefined bits. Number of children must match number of bits of one of the integer types. For example the decompiler doesn’t have to model the complete x87 FPU status word since most of the time only a few bits (used for testing the comparison result) matter.
- EXTRACT_BITS(value, numBits, srcPos, destPos): extracts numBits from the src at the srcPos (and going to the MSB) and shift them to destPos afterwards. So something like “((value >> srcPos) & maskOf(numBits))<<destPos”.
- SEGMENT2ADDR(segmentReg)
- TERNARY(cond, trueValue, falseValue)
- CONSTRUCT(named1, named2,…), NAMED(name, value) and EXTRACT(base, name) for supporting multiple return values
- ISDEF(x): false iff x is undefined
- ACCESS_ARRAY(base, index), ACCESS_MEM(base, name), ACCESS_UNION(base, name): generated by the full type analysis to denote different access types.
- MARKER_SIGNED(x), MARKER_UNSIGNED(x): Related to full type analysis. Generated early but then converted to type traits.
Some More Details and Design Notes
All memory access is modeled with expressions. There is a load expression which takes the address. The basic type of the load expression determines the access width. The store expression takes the address and the value to store. The basic type of the store expression is void.
An expression can have a side-effect (memory store or function which isn’t annotate as side-effect free). Such expressions are only valid at the top-level of the RHS of the assignment statement. This means that each statement has at most one side-effect. The return value and jump conditions are side-effect free. So the list of statements are the only ordering feature of the IR. Or in other words: there is no comma operator.
In computer science a basic block has two outgoing edges. Supporting multiple outgoing edges has benefits and I didn’t encounter (or maybe didn’t see) any disadvantages. One benefit is the easy construction of short circuit boolean expressions. It is easy to see that:
if(cond1) goto block 3;
if(cond2) goto block 3;
goto block 4;
can be transformed to:
if(cond1 || cond2) goto block 3;
goto block 4;
The and case can be transformed from:
if(!cond1) goto block 4;
if(!cond2) goto block 4;
goto block 3;
to
if(!cond1 || !cond2) goto block 4;
goto block 3;
and finally
if(cond1 && cond2) goto block 3;
goto block 4;
If the jumps are not together we can move a jump up the list by adding the negated condition of the previous jump. So
if(cond1) goto block 3;
if(cond2) goto block 4;
if(cond3) goto block 3;
goto block 5;
can be converted to
if(cond1) goto block 3;
if(!cond2 && cond3) goto block 3;
if(cond2) goto block 4;
goto block 5;
and finally
if(cond1 || (!cond2 && cond3)) goto block 3;
if(cond2) goto block 4;
goto block 5;
Most of the expression types require that their children have the same basic type. So you can not add a 2 byte integer to a 2 byte float. Most of the expression types require that the parent basic type and the child(ren) basic type is the same. There are of course type conversion expressions like “unsigned extend”. The parameters of a function call have to match their basic type the signature. This means that for functions with variable parameter types (varargs in C) their signature has to be forked and made concrete for each call site based on for example the format string. Also the basic type of the LHS and RHS of the assignment statement have to be equal. In general the checks related to the basic type caught quite a few bugs. The most recent one using lea with an address override prefix.
Repeat after me “Registers are good, memory is evil!” Both are aliased: when the instruction inc eax is executed this will also change ax, ah and al. That is the aliasing of registers. This aliasing is broken up during the transformation into the IR, meaning that the instruction will create multiple assignment statements:
reg_eax = reg_eax+1;
reg_ax = getLowWord(reg_eax);
reg_ah = getHighByte(reg_ax);
reg_al = getLowByte(reg_ax);
So there is no aliasing anymore from registers in the IR. The register expressions will also be transformed into SSA and the decompiler can easily reason about their usage. For memory this is sadly not the case. This is especially important for local stack variables but also for memory in general. In the best case the decompiler can reason that a certain stack range is not aliased and convert this to a register expression. It is possible that such a register is later removed since no code depended on its value.
The SSA form of the IR only differs in two details from the non-SSA form:
- register expressions (which are the only ones which are versioned currently) get a version suffix. So “reg_a” becomes “reg_a_2”. Look at the example below.
- assignment statements with PHI expressions in the RHS are added where required. Such statements are always at the start of a block.
Note that holdec only puts register expressions under SSA but it tries to convert local variables to register expressions and propagates memory values if it knows that these values do not change. One side-effect here is that the user can declare a certain memory areas as volatile meaning that they can change by other means (hardware, other threads, OS, …).
Per se the addresses of the instructions are not carried over into the IR. So neither a statement nor a block knows its origin. I didn’t find any good reason for carrying this information. After all the passes the blocks and statements are usually so heavy modified that it doesn’t matter where they originated. There are/were exceptions when the instruction address is required for identification purposes in relation to the info file.
Holdec supports the return of multiple values. This makes for example modeling CPU instructions easier (like the values from the “cpuid” instruction) and is required to describe functions found in the wild (which may even return data in the flags register). C allows you to pass pointers which are used by the called function to return multiple values. Or structs are used. Common in these approaches is that they use memory. And memory is evil. So there are three magic expressions in holdec to allow to return multiple values without using memory.
// Code in the called method:
return Construct(Named("result1", 42),
Named("result2", 12.34));
// Calling method and extracting:
// reg_a has a dummy basic type here
reg_a = theMethod(...);
reg_int_value = Extract(reg_a, "result1");
reg_float_value = Extract(reg_a, "result2");
A function has exactly one return statement. This is easy to acomplish in the blocks-of-assembler-lines stage by adding a new block and replacing the “ret”s with jumps to the new block. But there are also methods which do not return. There are a lot of different ways: swift uses breakpoints when on overflow is detected, libc has exit(), then there is pthread_exit(), linux has sys_exit and other systems have other means. If the decompiler doesn’t know about this property it will decompile after the non-returning instruction yielding incorrect output. The first step is of course recognizing such cases. The second is how to model it in the IR. My first attempt was a terminated statement. This caused all sort of special cases all over the place in the code which didn’t feel right. I later changed this to insert an endless loop with a special body after such an instruction:
block30:
(void) exit(0);
goto block31;
block 31:
__postNoReturnMarker();
goto block31;
Such special loop is detected during output and a string “// not reached” is shown instead.
The other way of contradicting the invariant of having exactly one return statement are functions which do not return at all. For this another special builtin function is added and the whole function body is wrapped in a new condition which is also skipped in the output:
void myexit() {
if(__alwaysTrue()) {
printf("ERROR: ...", ...);
exit();
// not reached
}
return;
}
A list of the basic types:
| Type | Suffix | C syntax |
| void | v | void |
| boolean | z | bit |
| 1 byte integer | b | d1 |
| 2 byte integer | w | d2 |
| 4 byte integer | l | d4 |
| 8 byte integer | q | d8 |
| 16 byte integer | o | d16 |
| 1 byte float | c | f1 |
2 byte float
| h | f2 |
| 4 byte float | s | f4 |
| 8 byte float | d | f8 |
| 10 byte float | e | f10 |
| 16 byte float | g | f16 |
The suffix can be seen in some a verbose output variant:
reg_pp_20.l = PHI(reg_var5_0.l, reg_var5_1.l).l;
reg_pp_19.q = PHI(reg_var4_0.q, reg_var4_1.q).q;
reg_pp_18.q = PHI(reg_var3_0.q, reg_var3_1.q).q;
reg_pp_17.q = PHI(reg_var2_0.q, reg_var2_1.q).q;
reg_ao_0.l = LOAD(ADD(reg_pp_19.q, 12.q).q).l;
reg_ap_0.l = UNSIGNED_EXTEND(LOAD(ADD(reg_pp_19.q, 25.q).q).b).l;
The names of register expressions do not match the physical register names you may expect. So you see for i386 “reg_a” instead of “reg_eax” or “reg_Bl” instead of “reg_es”. There are multiple reasons:
- the renaming makes the names shorter and easier to understand (my opinion)
- for addressing vector lanes you would need to include special char like []
- there are other sources of register expressions than physical registers. Examples are the number of elements on the x87 FPU stack or register expressions from converting local stack memory.
Comparing with other IRs
The IR of Hex-Rays (called microcode) is nicely described in a talk of Ilfak Guilfanov at a conference. One example from this talk are the four instructions:
004014FB mov eax, [ebx+4]
004014FE mov dl, [eax+1]
00401501 sub dl, 61h ; 'a'
00401504 jz short loc_401517
which have the following initial 20 microinstructions
2. 0 mov ebx.4, eoff.4 ; 4014FB u=ebx.4 d=eoff.4
2. 1 mov ds.2, seg.2 ; 4014FB u=ds.2 d=seg.2
2. 2 add eoff.4, #4.4, eoff.4 ; 4014FB u=eoff.4 d=eoff.4
2. 3 ldx seg.2, eoff.4, et1.4 ; 4014FB u=eoff.4,seg.2,(STACK,GLBMEM) d=et1.4
2. 4 mov et1.4, eax.4 ; 4014FB u=et1.4 d=eax.4
2. 5 mov eax.4, eoff.4 ; 4014FE u=eax.4 d=eoff.4
2. 6 mov ds.2, seg.2 ; 4014FE u=ds.2 d=seg.2
2. 7 add eoff.4, #1.4, eoff.4 ; 4014FE u=eoff.4 d=eoff.4
2. 8 ldx seg.2, eoff.4, t1.1 ; 4014FE u=eoff.4,seg.2,(STACK,GLBMEM) d=t1.1
2. 9 mov t1.1, dl.1 ; 4014FE u=t1.1 d=dl.1
2.10 mov #0x61.1, t1.1 ; 401501 u= d=t1.1
2.11 setb dl.1, t1.1, cf.1 ; 401501 u=dl.1,t1.1 d=cf.1
2.12 seto dl.1, t1.1, of.1 ; 401501 u=dl.1,t1.1 d=of.1
2.13 sub dl.1, t1.1, dl.1 ; 401501 u=dl.1,t1.1 d=dl.1
2.14 setz dl.1, #0.1, zf.1 ; 401501 u=dl.1 d=zf.1
2.15 setp dl.1, #0.1, pf.1 ; 401501 u=dl.1 d=pf.1
2.16 sets dl.1, sf.1 ; 401501 u=dl.1 d=sf.1
2.17 mov cs.2, seg.2 ; 401504 u=cs.2 d=seg.2
2.18 mov #0x401517.4, eoff.4 ; 401504 u= d=eoff.4
2.19 jcnd zf.1, $loc_401517 ; 401504 u=zf.1
And after some steps the final microcode instruction:
jz [ds.2:([ds.2:(ebx.4+#4.4)].4+#1.4)].1, #0x61.1, @7
I put these four instructions and some additional code into a full example to look at how holdec sees these instructions. The blocked assembler stage is:
08049079.0+3 mov eax,ds:[ebx+0x4]
0804907c.0+3 mov dl,ds:[eax+0x1]
0804907f.0+3 sub dl,0x61
08049082.0+2 l.jz L6
In the next step the initial IR of this block is as follows
reg_a = LOAD(SEGMENT2ADDR(reg_Bk) + reg_b + 4);
reg_l = _holdec_getLowWordL(reg_a);
reg_Bb = _holdec_getLowByteL(reg_a);
reg_w = _holdec_getHighByteL(reg_a);
reg_Be = LOAD(SEGMENT2ADDR(reg_Bk) + reg_a + 1);
reg_d = _holdec_setLowByteL(reg_d, reg_Be);
reg_o = _holdec_setLowByteW(reg_o, reg_Be);
reg_eflags_sf = BIT_TEST(7, reg_Be + 97 * -1);
reg_eflags_zf = reg_Be + 97 * -1 == 0;
reg_eflags_pf = _holdec_ia32_parity(reg_Be + 97 * -1);
reg_eflags_af = _holdec_ia32_adjustFlagAddSub(reg_Be, 97, reg_Be + 97 * -1);
reg_eflags_of = SUB_BORROWS_SIGNED(reg_Be, 97);
reg_eflags_cf = reg_Be < 97;
reg_cmp_as = reg_eflags_af;
reg_cmp_b = MARKER_UNSIGNED(reg_Be) < MARKER_UNSIGNED(97);
reg_cmp_be = MARKER_UNSIGNED(reg_Be) <= MARKER_UNSIGNED(97);
reg_cmp_ds = reg_eflags_df;
reg_cmp_l = MARKER_SIGNED(reg_Be) < MARKER_SIGNED(97);
reg_cmp_le = MARKER_SIGNED(reg_Be) <= MARKER_SIGNED(97);
reg_cmp_o = reg_eflags_of;
reg_cmp_p = UNDEF;
reg_cmp_s = UNDEF;
reg_cmp_z = reg_Be == 97;
reg_Be = reg_Be + -97;
reg_d = _holdec_setLowByteL(reg_d, reg_Be);
reg_o = _holdec_setLowByteW(reg_o, reg_Be);
if(ISDEF(reg_cmp_z) ? reg_cmp_z : reg_eflags_zf) goto L6;
goto L3;
To understand these you need the translation table:
| reg_a | eax |
| reg_b | ebx |
| reg_d | edx |
| reg_l | ax |
| reg_o | dx |
reg_w
| ah |
| reg_Bb | al |
| reg_Be | dl |
| reg_Bk | ds |
Some aspects I want to point out:
- SEGMENT2ADDR(reg_x) will become zero if reg_x is not modified in the function
- there is always the struggle to decide which modeling tool to use: low-level expressions like AND and OR, higher level ones like SUB_BORROWS_SIGNED or builtin functions like _holdec_ia32_parity. There will be another blog post about this topic.
- the MARKER_SIGNED/MARKER_UNSIGNED expressions are related to the full type analysis. Which is also a topic for another blog post.
- There is the leaf expression UNDEF (and also NOT_MODELED) and a predicate expression ISDEF.
- There are two ways of flag tracking: low-level (reg_eflags_*) is modeled after the bits in the eflags register and high-level (reg_cmp_*) matching the condition codes jumps and other instructions have. As you can see the high-level ones are used if possible. If the flag register is accessed directly (for example with lahf) the low-level ones are used.
After bringing the code into SSA form and remove the unused registers we get:
reg_a_2 = LOAD(SEGMENT2ADDR(reg_Bk_0) + reg_b_0 + 4);
reg_Be_0 = LOAD(SEGMENT2ADDR(reg_Bk_0) + reg_a_2 + 1);
reg_eflags_zf_3 = reg_Be_0 + 97 * -1 == 0;
reg_cmp_z_3 = reg_Be_0 == 97;
if(ISDEF(reg_cmp_z_3) ? reg_cmp_z_3 : reg_eflags_zf_3) goto L6;
goto L3;
Register values are propagated:
reg_a_2 = LOAD(LOAD(InitStackPointerReg + 8) + 4);
reg_Be_0 = LOAD(LOAD(LOAD(InitStackPointerReg + 8) + 4) + 1);
reg_eflags_zf_3 = LOAD(LOAD(LOAD(InitStackPointerReg + 8) + 4) + 1) == 97;
reg_cmp_z_3 = LOAD(LOAD(LOAD(InitStackPointerReg + 8) + 4) + 1) == 97;
if(LOAD(LOAD(LOAD(InitStackPointerReg + 8) + 4) + 1) == 97) goto L6;
goto L3;
Unused registers are removed again:
if(LOAD(LOAD(LOAD(InitStackPointerReg + 8) + 4) + 1) == 97) goto L6;
goto L3;
End finally after the pass which looks at the types of certain stack areas:
if(LOAD(LOAD(LOAD(&argv) + 4) + 1) == 97) goto L6;
goto L3;
Thank you for reading and please send questions or feedback via email to holdec@kronotai.com or contact me on Twitter.
]]>