
The following describes the design of holdec but also outlines some of the problems a decompiler writer has to think about. The actual decompiler program is of course more complex because there are low-level problems not mentioned here. So let us speak about the design of holdec.
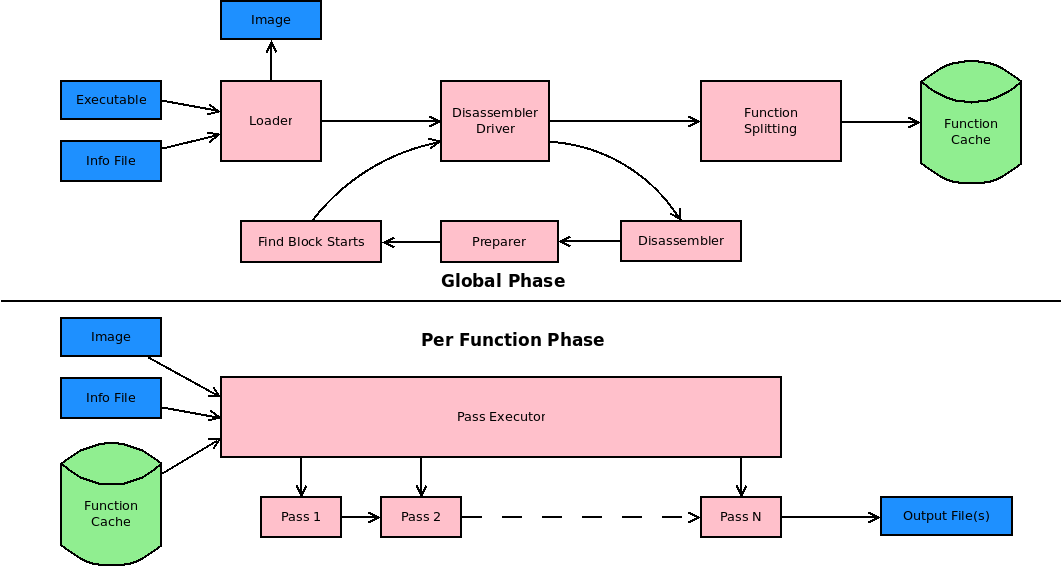
Holdec has two major phases: a global phase and a per function phase. The output of the first one are cached assembler lines of each identified function. In the second phase these are read and transformed into human readable output.
Global Phase
The global phase starts with the Loader. This one is quite straightforward:
- it identifies the file format,
- creates an image which has all the sections loaded at the correct addresses and performs relocations and other operations the OS loader would do and
- provide the relevant information (symbols, sections, start address, …).
The Disassembler Step is the second step. It consists of the driver, multiple CPU specific disassemblers and multiple CPU specific preparers. There is nothing decompiler specific about the disassemblers: you can use any disassembler library. I wrote 2 of the 3 disassembler in holdec myself. Mostly because I wanted to do so and no suitable libraries were available in Java (the language holdec is implemented in). I open sourced Jarmo (the Arm64 disassembler) on Github. To make the next steps easier x86 prefixes start with a slash and the size of the instruction is added to each line (e.g. "0x4200+3 nop" for a 3 byte nop). Also coming from M68k I found and still think that specifying the operand size both in Intel syntax (mov DWORD PTR [ecx],0x0) and AT&T syntax movl $0x0,(%ecx)) is not easy to parse. So the holdec x86 disassembler adds a prefix resulting in l.mov ds:[ecx],0x0 (see also xkcd). So while these changes make the disassembled instructions a bit more similar in their general syntax they are still very much CPU specific.
The Preparers are sometimes magic (a blog post about them is coming) but serve two purposes:
- transform the assembler instructions so that jumps and calls are visible and the control will not change later and
- reduce the work for later steps by expressing instructions with other instructions.
In the first category are jump tables which are identified by patterns and the indirect jump is replaced with an indexed jump (range of valid values and for each value the target address). Also in the first category are the handling of instructions/functions/OS syscalls/… which terminate the running program. These instructions have to be annotated. A third example is undoing tail recursion elimination. In the second category are mostly instructions from ia32 like JECXZ, XCHG, CMOVcc, the string instructions, everything with a rep prefix and so on. But also CSEL and friends from AARCH64 can be expressed with simpler instructions and thus reduce the surface area of later stages.
Before we discuss the driver I have to touch another design decision: the Info File. The name is not great but you know about the hard problems of computer science… The general idea is that the decompiler can be run without human interaction but still with human input. The human input is saved in a file (the info file) and is the second input (in addition to the binary) for the non-interactive decompilation. While a human can provide input (for example a function signature) the decompiler also updates the info file (however never overwriting something from a human) with information such as also functions found and the assumed signatures (based on calling conventions and usage). But the decompiler will also write other information (like jump tables) to the info file which the human may change. In general it is a good idea to re-run the decompiler when the info file is changed.
Coming back to the Dissembler Driver. The task of the driver is:
- to disassemble all code areas (=code sections minus data areas in the code sections)
- to identify all block starts
Regarding the data areas in code sections: while the object format like ELF will specify which areas contain code not all of the section has to contain code. In addition you have object formats which don’t have sections at all. Constants (string, integer, floating point) and jump tables are commonly found in code sections. These can be specified in the info file and the driver will exclude them.
There are at least the following sources for block starts:
- program start address
- jump targets
- call targets
- next instruction after an unconditional control transfer (jump, return)
- code section start addresses
- next byte after a data area in a code section
- function start addresses from the object format
- address in the inside of a code section. Such an address may occur in a data section. Reloc informations can help here.
So in a loop the driver runs the dissembler on all code areas with a linear sweep, let the preparer run over the whole list of assembler instructions and searches for new block starts. If no new starts are found the loop ends. The driver also takes care of overlapping instructions. But this is a topic of another blog post.
The third step is the Function Splitting. For each known function collect all blocks and write the assembler lines for a file. Note that blocks can be shared by multiple functions. Thus the result of the global phase is a set of cached assembler lines for each known function.
Per Function Phase
Holdec allows you to select on the command line which functions should be decompiled. This can be single function, all functions or most function (all function but exclude some known common ones like libc startup code). From the set of functions to decompile each is decompiled on its own. The only information transfer is through the info file. So I can repeat here it may make sense to re-run the decompiler after a info file change.
The decompilation of a function is nicely split into passes. There are currently around 50 different pass types and in total around 90 passes are executed. Each pass writes some output (assembler lines, internal representation, dot file for graphviz) but during non-development only the output of the last passes are used.
The major passes for the start are:
- split assembler lines into blocks
- transform each assembler line into the internal representation (aka parsing, lifting or rewriting). This pass is of course CPU specific while the remaining ones are CPU agnostic.
- transform to SSA
- remove unused variables. A major milestone is reached after this pass since the parser has to generate a lot of statements which may or may not be used. This pass reduces the amount of statements to 5-15%.
- simplification (aka symbolic execution). Execute a lot of rules which make expressions simpler (x+3==4 => x==1, x XOR x => 0) or canonical (x<=9 => x<10). This also includes a boolean minimization engine using Karnaugh maps.
- register value propagation
- memory value propagation
In the middle special one-time passes are executed and the basic ones (remove unused variables, simplification and register value propagation) are repeated after each special one. Example of such special passes are:
- recognize division by multiplication
- undo SSA and transform to SSA again (this it not a nop and allows further passes a fresh view on the program)
- load constants (string, integer, float) from read-only sections
- recognize format strings (printf, scanf and co)
- replace stack area/variable with real variable under certain conditions
Passes executed in the end are:
- undo SSA
- recognize high level control flow (heavy)
- transform code based on the high level control flow (for example introduce induction variable into a loop) (heavy)
- optional: full type recognition (heavy)
- output in multiple formats: as high level C-like source code, blocks with statements and/or .dot for graphviz
In the following blog posts I want to go into some detail for specific parts. So stay tuned.
Thank you for reading and please send questions or feedback via email to holdec@kronotai.com or contact me on Twitter.
]]>